Linux内核网卡中断分配不均调优
本文最后更新于:2023年9月21日 下午
Linux内核网卡中断分配不均衡调优
查看CPU具体中断情况
/proc/interrupts 文件中可以看到各个 CPU 上的中断情况。
1 | |
/proc/irq/[irq_num]/smp_affinity_list 可以查看指定中断当前绑定的 CPU。
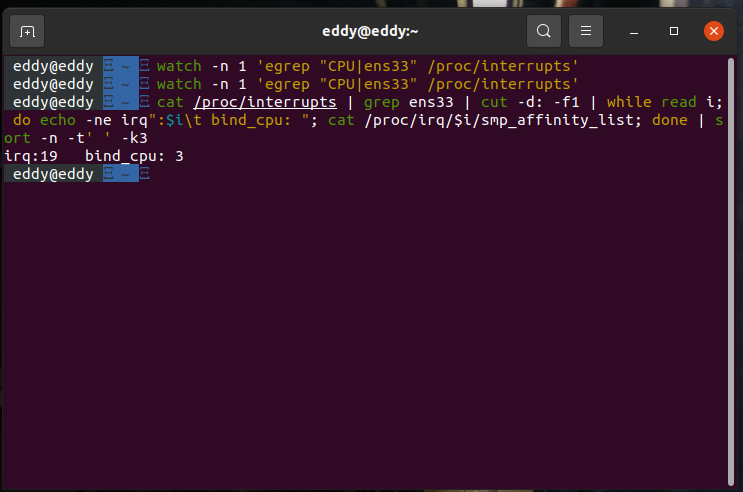
使用以下命令可查看对应中断绑定的CPU核:
1 | |
输出
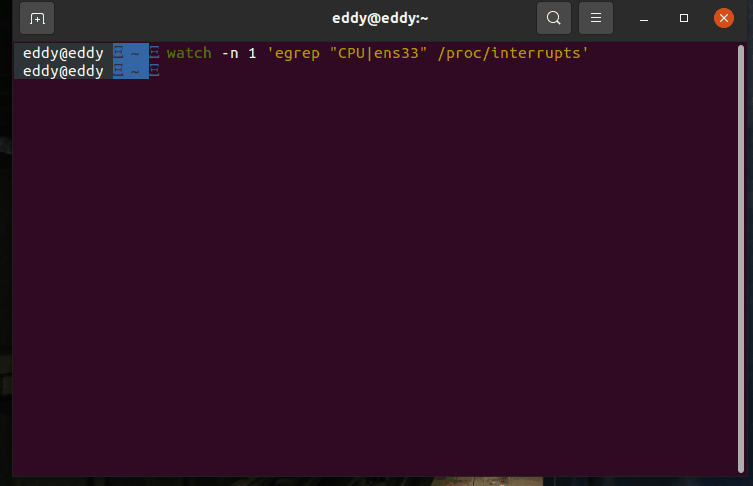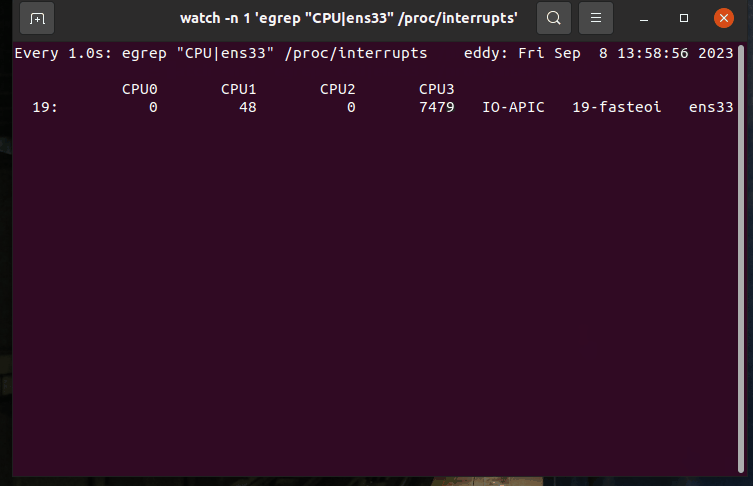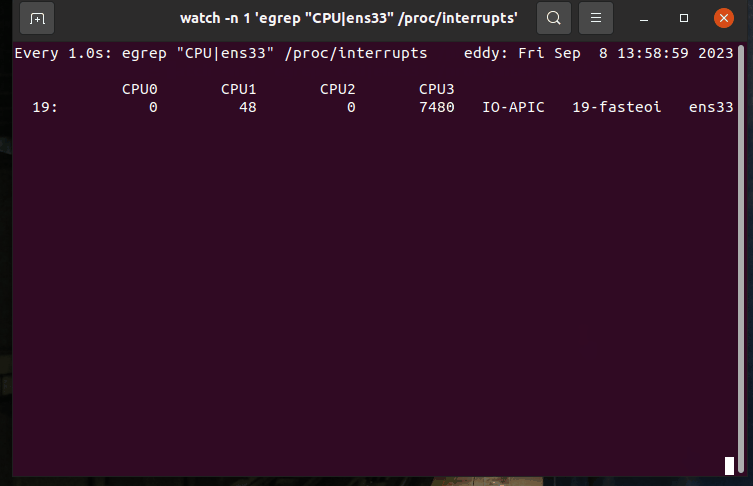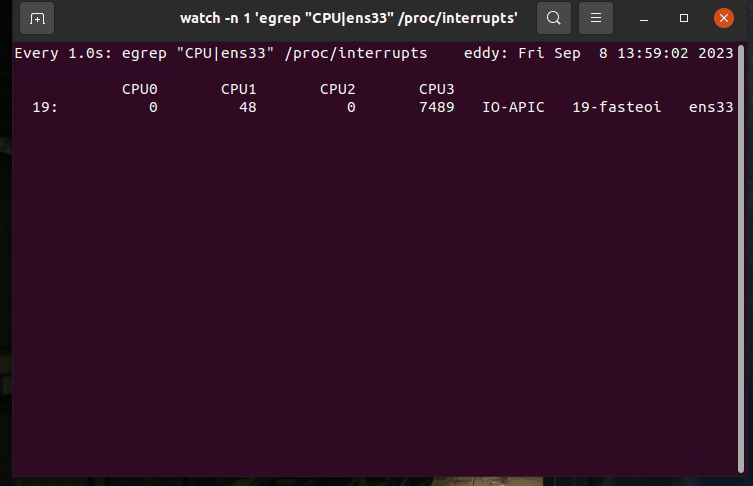
查找对应网卡中断触发情况
1 | |
输出
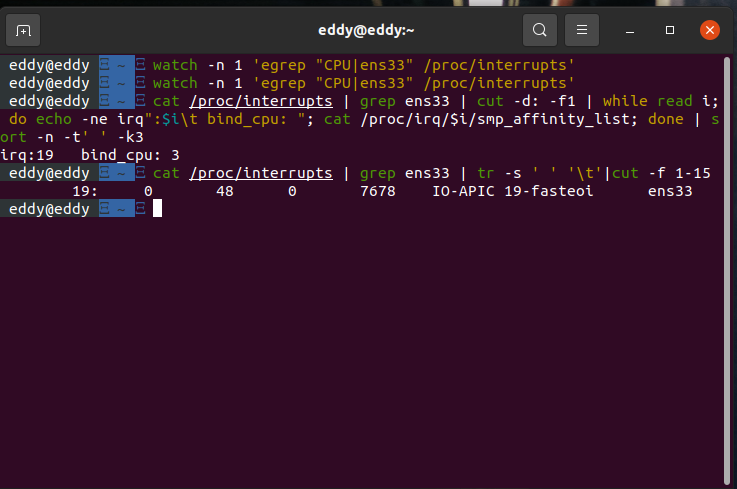
如输出所示,中断的处理大部分被CPU3所处理。
中断绑定
中断绑定即设置中断的CPU Affinity,让中断只在指定CPU核心上进行响应。
Kernel 2.4开始支持把不同的硬件中断请求(IRQ)分配到特定的CPU上,绑定技术被称为SMP IRQ Affinity。
/proc/irq/[irq_num]/smp_affinity
smp_affinity文件用于存放CPU位掩码(16进制),修改该文件中的值可以改变 CPU 和某中断的亲和性。
使用CPU列表手动修改网卡各队列中断绑定
1 | |
/proc/irq/[irq_num]/smp_affinity_list
该文件存放的是 CPU 列表(十进制)。注意,CPU 核心个数用表示编号从 0 开始,如 CPU0, CPU1 等。
使用CPU列表手动修改网卡各队列中断绑定
1 | |
查询中断分布
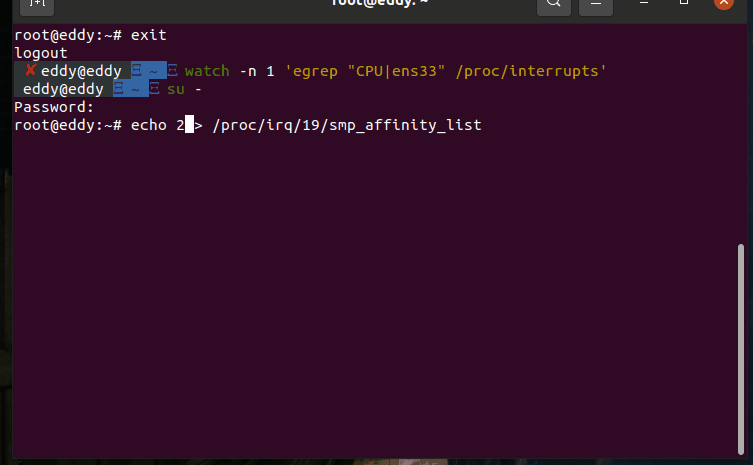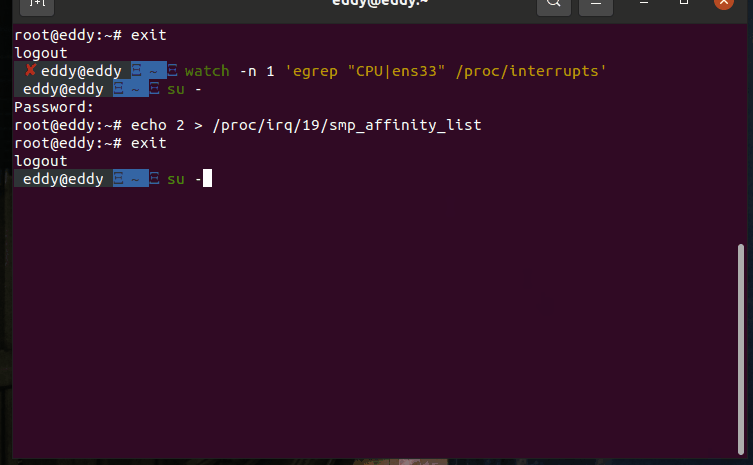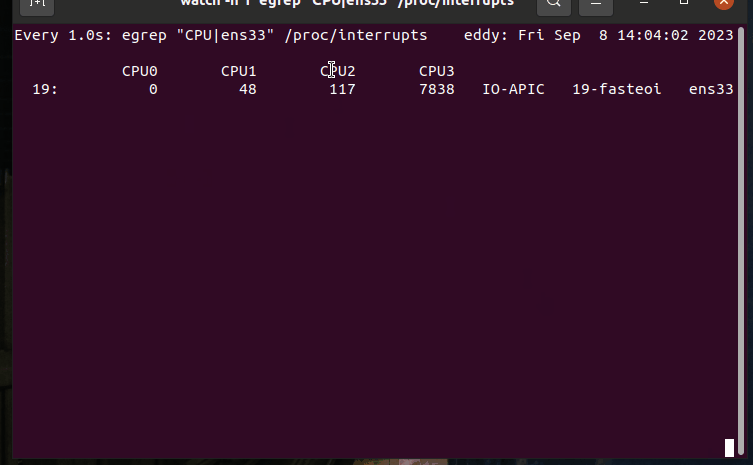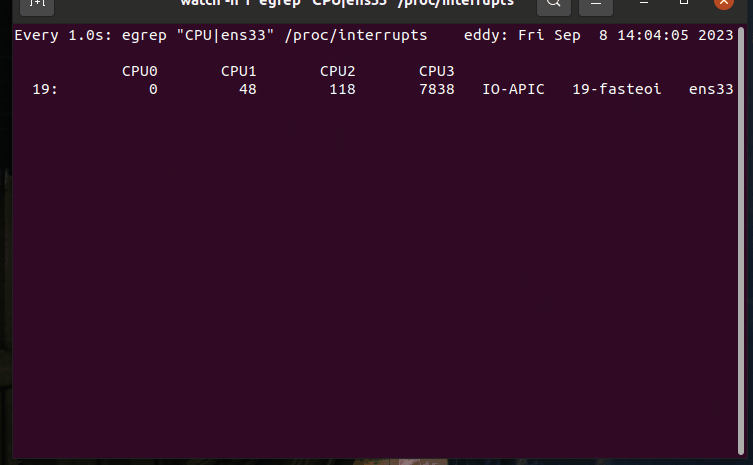
网络数据处理监控
/proc/net/softnet_stat
/proc/net/softnet_stat用于网络数据处理监控。
1 | |
/proc/net/softnet_stat的每一行对应一个struct softnet_data数据结构,每个CPU一个,值之间用一个空格分隔,并以十六进制显示。
- 第一个值,
sd->processed,是处理的网络帧数。如果您使用以太网绑定,这可能会超过接收到的网络帧总数。有些情况下,以太网绑定驱动程序会触发网络数据重新处理,同一数据包将使sd->processed计数增加不止一次。 - 第二个值,
sd->dropped,是因处理队列没有空间而丢弃的网络帧数。稍后再谈。 - 第三个值,
sd->time_squeeze,(如我们所见)是net_rx_action循环因消耗预算或达到时间限制而终止的次数,但仍然可以完成更多工作。如前所述,增加budget可以帮助减少这种情况。 - 接下来的 5 个值始终为 0。
- 第九个值,
sd->cpu_collision,是在发送数据包尝试获取设备锁时发生冲突的次数。本文讨论的是接收,因此下面不会看到这个统计量。 - 第十个值,
sd->received_rps,是唤醒此 CPU 通过处理器间中断处理数据包的次数。 - 最后一个值,
flow_limit_count,是达到流量限制的次数。流量限制是可选的Receive Packet Steering功能,稍后会探讨到该特性。
批量配置中断亲和性
1 | |
参考
译|Monitoring and Tuning the Linux Networking Stack: Receiving Data (cyningsun.com)
关于网卡中断不均衡问题及其解决方案 - Weir’s Note (leeweir.github.io)
Monitoring and Tuning the Linux Networking Stack: Sending Data | Packagecloud Blog
Linux性能优化(十六)——中断绑定_51CTO博客_linux 中断架构
Linux 多核下绑定硬件中断到不同 CPU(IRQ Affinity)-阿里云开发者社区 (aliyun.com)
[译1]linux网络栈监控及调优:数据接收-电子工程专辑 (eet-china.com)
第 34 章 调整网络性能 Red Hat Enterprise Linux 8 | Red Hat Customer Portal